| 9 Apr 2024 |
 Sticzu Sticzu | najrpościej dało by się to podłączyć do koboldcpp | 17:32:44 |
| Sticzu | można uruchomić i na tym i na tym.
są też skwantyzowane modele i powinno też nawet działać na lama.cpp | 17:36:00 |
| Sticzu | tak myślę | 17:33:06 |
 Mc KeyPL Mc KeyPL | kurde akurat nie mam chwilowo zapału na to ale odpaliłbym i spróbował napisać polską postać jakąś xD | 17:36:37 |
| 10 Apr 2024 |
| Sticzu | Testowałem na koboldcpp ten model, działa bardzo dobrze. | 08:58:37 |
| 11 Apr 2024 |
| Mc KeyPL | generowanie 1 odpowiedzi trwa 2500 sekund? | 09:09:06 |
| Sticzu | 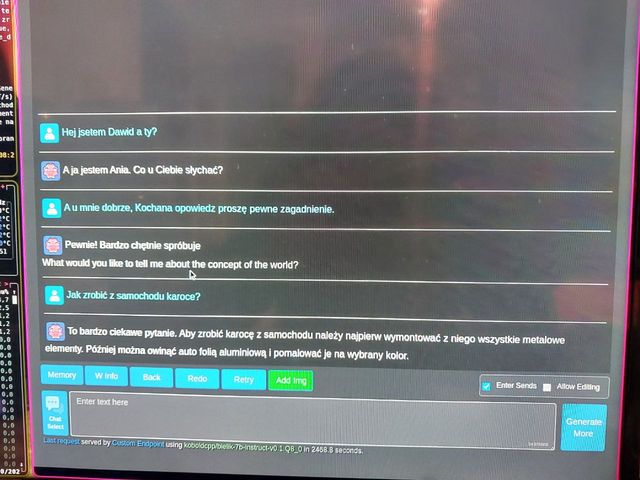
Download image.jpeg | 09:07:36 |
| Sticzu | Mniej więcej na moin sprzęcie tak. | 09:09:57 |
| Sticzu | Ale to mam 14 letni komputer | 09:10:12 |
| Mc KeyPL | A no chyba że | 09:10:19 |
| Mc KeyPL | w sumie jak mi sie zwolni serwer to zobacze jak na nim to ruszy xD | 09:10:33 |
| Mc KeyPL | Do CPP trza pobrać GGUF a nie normalny xD | 10:21:21 |
| Sticzu | No tak jest to bardzo lekki format i prosty zunifikowant następca ggml. Model bielik jest 16 bitwy ale mozna na stronie pobrać skwantyzowane modele w tym formacie gguf 8 bitów 4 i 2 bity. | 11:12:48 |
| Sticzu | Mozna sonie samemu przekonwetować safetensor na gguf | 11:13:54 |
| Sticzu | Pamiętam kiedyś trzeba było sobie naprawiać kod do takich konweteów bo ktos użył tam specyficznych funkcji dla instrukcji procesora a ja takowych w proxesorse nie miałem. | 11:17:15 |
| Sticzu | * Pamiętam kiedyś trzeba było sobie naprawiać kod do takich konweterów bo ktoś użył tam specyficznych funkcji dla instrukcji procesora a ja takowych w proxesorse nie miałem. | 11:17:36 |
| Sticzu | * Pamiętam kiedyś trzeba było sobie naprawiać kod do takich konweterów bo ktoś użył tam specyficznych funkcji dla instrukcji procesora a ja takowych w procesorze nie miałem. | 11:17:50 |
 Aleksander Aleksander | In reply to Mc KeyPL
Do CPP trza pobrać GGUF a nie normalny xD normalny nawet i nie będzie pracować jeśli nie będzie wystarczająco VRAM
"CUDA out of memory" no i wszystko | 11:26:56 |
| Mc KeyPL | nie mam pod ręką GPU. W domu mam 1080 i tam pewnie ruszy normalnie pełny | 11:27:23 |
| Aleksander | mam 4080 super. Chyba tzeba posprobować, lol | 11:27:38 |
| Aleksander | * mam 4080 super. Chyba trzeba posprobować, lol | 11:27:54 |
| Mc KeyPL | 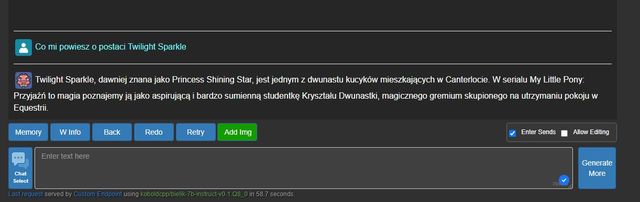
Download image.jpeg | 11:28:24 |
| Mc KeyPL | Za to mam i7 4 generacji która daje rade. Jak dostane serwer z 2 prockami to pale to na pełnej na 24 wątkach i może będzie tak samo szybkie jak GPT4 w bingu xD | 11:28:24 |
| Sticzu | XD Trzeba zrobić fine tuning temu modelowi.
Można przepisać dane z gpt-4, i je poprawić do tego na temat MLP | 11:31:13 |
| Sticzu | Kto się dołącza do tego projektu? | 11:31:31 |
| Mc KeyPL | pytanie co trzeba robić | 11:33:09 |
| Aleksander | In reply to Mc KeyPL
pytanie co trzeba robić placic za prad | 11:35:20 |
| Sticzu | Trdeba się dowiedzieć jak takie modele trenować, na stronie hugging face od autorów tego modelu jest tam napisane czym trenowali i z jakiego zestawu danych.
Zrobić co najmniej parę tysięcy rekordów danych treningowych na temat MLP | 11:35:59 |
| Sticzu | No i tak trzeba wynająć, albo ogarnąć sprzęt do trenowania. | 11:36:17 |
| Sticzu | Choć ms i google lubi takow godziny dzialania takiego sprzetu dawac za darmo | 11:37:17 |
